
Performance Evaluation of Weather and Climate Prediction Applications on Intel's Ice Lake Processor
1. Intel's third-generation Xeon Scalable processors (Ice Lake) offer a major boost in performance
Intel launched its new third-generation Intel Xeon Scalable processor series (Ice Lake) this year. Compared to the previous-generation Xeon Scalable processor series (Cascade Lake), this third-generation chip features the following enhancements:
Upgraded manufacturing process (14nm to 10nm) and increased theoretical transistor density (by 2.7 times);
Upgraded micro-architecture and improved IPC (by 20%);
Increased maximum number of cores (28 to 40), optimized AVX2/AVX512 instruction sets, and increased L3 cache capacity of each core (1.375 MB to 1.5 MB);
Greatly improved IO performance, increased number of memory channels (6 to 8), and shortened memory access latency. The PCIe protocol has been upgraded from PCIe 3.0 to PCIe 4.0. UPI bus bandwidth has been slightly improved.
Do all of these hardware performance enhancements boost the application performance? Especially for weather and climate prediction applications that require a large number of CPU cores for large-scale parallel computing? Generally, weather and climate prediction applications have a relatively high BF Ratio, which means the performance of such applications is highly dependent on memory bandwidth and FLOPS (floating point operations per second). For these types of applications, the above enhancements of the third-generation Xeon Scalable processors are truly amazing and much-anticipated, especially the higher FLOPS resulting from the optimized AVX instruction sets and the improved memory bandwidth due to more memory channels. How then do the third-generation Xeon Scalable processors improve the performance of weather and climate prediction applications compared to Intel's previous-generation processors? We conducted an evaluation and analysis using several widely used weather and climate forecast models, including WRF (Weather Research and Forecasting) model, MPAS-A (Model for Prediction Across Scales-Atmosphere), and CESM (Community Earth System Model).
In the following comparative test, we built a test environment in Kaytus’ HPC laboratory for different applications, with the computing nodes using the 6230, 6248, and 6258R processors in the second-generation Xeon Scalable processor series (Cascade Lake) and 8358 processor in the third-generation Xeon Scalable processor series (Ice Lake).
2. Comparison of WRF Performance
About WRF
The WRF Model is a next-generation mesoscale numerical weather prediction system designed for both atmospheric research and operational forecasting applications. It is jointly developed by the National Center for Atmospheric Research (NCAR), the National Oceanic and Atmospheric Administration (represented by the National Centers for Environmental Prediction (NCEP) and the Earth System Research Laboratory), the U.S. Air Force, the Naval Research Laboratory, the University of Oklahoma, and the Federal Aviation Administration (FAA).
WRF Test Case
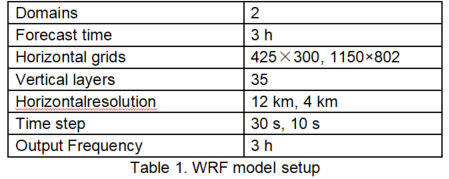
Table 1 shows the simulation domain area, temporal and spatial resolutions of the WRF test case. It is a two-domain run. The sizes of the coarse domain and the nest domain are 425×300 and 1150×802 with a spatial resolution of 12km and 4km, a time step of 30s and 10s, respectively. The number of vertical layers was 35. The forecast time was 3 hours, and data was output every 3 hours.
WRF Performance Testing Results
We tested the performance of WRF on theIntel 6230 Cascade Lake processor and 8358 Ice Lake processor by using 224 cores. The WRF model ran for 695 seconds on the 6230 processor platform and 489 seconds on the 8358 processor platform, with a 42% increase in performance on the latter platform (see Figure 1). This is largely because WRF is a compute-bound and memory-bound application, and the 8-channel memory architecture of the Ice Lake processor improved the memory bandwidth. In addition, the higher FLOPS and low-latency access to memory greatly contributed to the improved performance of WRF running on the 8358 processor platform.
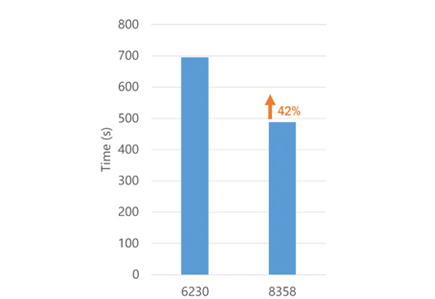
Figure 1. Comparison of WRF Performance on the 6230 and 8358 Processor Platforms
3. Comparison of MPAS-A Performance
About MPAS-A
MPAS-A (Model for Prediction Across Scales-Atmosphere), developed under the leadership of NCAR, is an across-scale prediction model that solves the fully compressible nonhydrostatic equations of motion. The model usesan unstructured centroidal Voronoi mesh (see Figure 2) and C-grid staggering of the state variables as the basis for the horizontal discretization. The unstructured variable resolution meshes can be generated having smoothly-varying mesh transitions so that the key simulation domains could have high resolution and the abrupt changes in physical quantities near the boundaries can be avoided.
MPAS-A Test Case
The MPAS-A test case is a 60 km global weather simulation with a time step of 360 seconds. Its forecast time is 2 hours, and it has 55 vertical layers.
Figure 2. A variable resolution MPAS Voronoi mesh from the MPAS-A official site
MPAS-A Performance Testing Results
We tested the performance of MPAS-A on theIntel 6230 Cascade Lake processor and 8358 Ice Lake processor by using 320 cores . The MPAS-A ran for 26.5 seconds on the 6230 processor platform and 15.5 seconds on the 8358 processor platform, with a 71% increase in performance on the latter platform (see Figure 3). Similar to WRF, MPAS-A is a memory-bound application. Therefore, the increased number of memory channels in the 8358 processor also helped boost the performance of MPAS-A.
Figure 4 shows the comparison of real-time FLOPS and memory bandwidth on a single computing node for the MPAS-Atest case running on the 6230 and 8358 processor platforms. As can be seen from the figure, the MPAS-A running on the 8358 processor platform delivered much higher performance than on the 6230 processor platform, as a result of the greatly improved FLOPS and memory bandwidth. Moreover, MPAS-A's BF Ratio was about 2.55 on the 6230 processor platform and about 2.40 on the 8358 processor platform. The reason for the slightly lower BF Ratio on the 8358 processor platform is the reduced LLC miss rate resulting from the additional L3 cache of each core.
Figure 3. Comparison of MPAS-A performance on the 6230 and 8358 processor platforms
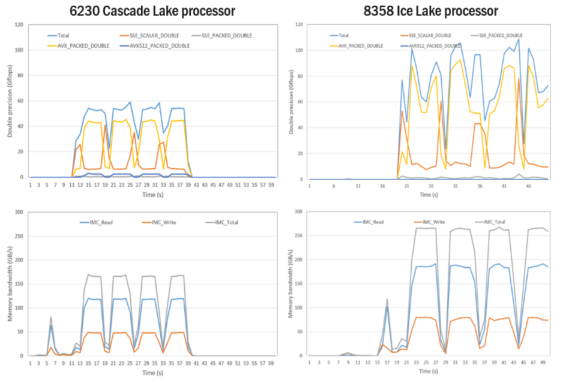
Figure 4. Comparison of real-time FLOPS and memory bandwidth on a single computing node for the MPAS-A test caserunning on the 6230 and 8358 processor platforms
4. Comparison of CESM Performance
About CESM
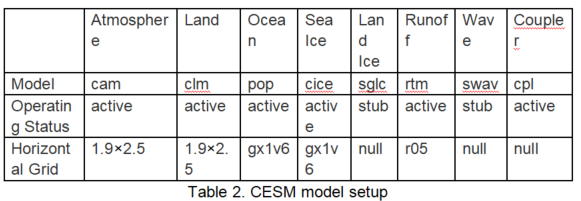
The Community Earth System Model (CESM) is a coupled climate model for simulating Earth’s climate system. Composed of separate models simultaneously simulating the Earth’s atmosphere, ocean, land, land-ice, and sea-ice, plus one central coupler component, CESM allows researchers to conduct fundamental research into the Earth’s past, present, and future climate states. The CESM is supported primarily by the National Science Foundation (NSF) and maintained by the Climate and Global Dynamics Laboratory (CGD) at NCAR.
CESM Test Case
In this test, the CESM is a fully coupled model with the f19_g16 grid. The forecast timeis one year.
CESM Performance Testing Results
The test is performed on 8358 Ice Lake processor and three Cascade Lake processors including 6248, 6230, and 6258R by using one node. CESM delivered significantly higher performance on the 8358 Ice Lake processor platform than on the Cascade Lake processors. The performance increased 94% over the 6230 processor, 83% over the 6248 processor, and 65% over the 6258R processor. CESM has a BF ratio that is close to 1 and is IO-bound and communication-bound. Therefore, the performance increase could not reach an ideal linear value and would drop somewhat, but could still reach 83% (compared to the 6248 processor) and 94% (compared to the 6230 processor).
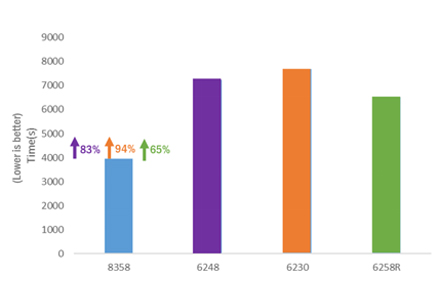
Figure 5. Comparison of CESM performance on different processor platforms
5. Conclusion
Given the amazing enhancements of Intel's new third-generation Xeon Scalable processors (Ice Lake), including the increased number of memory channels and optimized AVX2/AVX512 instruction sets, and considering the high BF ratio in weather and climate prediction applications, we tested and analyzed several widely used applications, including WRF, MPAS-A, and CESM on the HPC clusters built with the third-generation Xeon scalable processor, and performed a comparison with the second-generation Xeon processors. Using the same number of cores, the performance of WRF was improved by 42% and that of MPAS-A by 71% on the Ice Lake 8358 processor platform compared to the Cascade Lake 6230 processor platform. This is largely because WRF is a compute-bound and memory-bound application, and MPAS-A is also a memory-bound application. The 8-channel memory architecture of the Ice Lake processor improved the memory bandwidth. In addition, the higher FLOPS and low-latency access to memory greatly improved the performance of both WRF and MPAS-A running on 8358 processor platform. As for CESM that is not bounded by memory bandwidth, the significantly increased memory bandwidth and FLOPS of Ice Lake processor made CESM's performance increase by 82.7% over the 6248 processor, and 94.1% over the 6230 processor.