MotusAI ist eine von KAYTUS entwickelte KI-DevOps-Plattform für die Entwicklung und Bereitstellung von KI-Modellen. Sie unterstützt Unternehmen beim Aufbau effizienter Deep Learning-Entwicklungsplattformen, bei der einheitlichen Verwaltung und Planung von KI-Rechenressourcen und bei der effektiven Verbesserung der Nutzung von Rechenressourcen. MotusAI bietet KI-Entwicklungsingenieuren einen kompletten KI-Entwicklungssoftware-Stack und einen Entwicklungsprozess, der die Effizienz von Forschung und Entwicklung erheblich verbessert.

Eine GPU-Shared Scheduling-Strategie ermöglicht die gemeinsame Nutzung von GPU-Ressourcen auf einem Gerät und unterstützt die gemeinsame Nutzung von bis zu 64 Aufgaben pro GPU. Zuweisung und Isolierung in beliebiger Granularität werden unterstützt. Benutzer können GPU-Ressourcen dynamisch auf der Grundlage des GPU-Speichers anfordern.

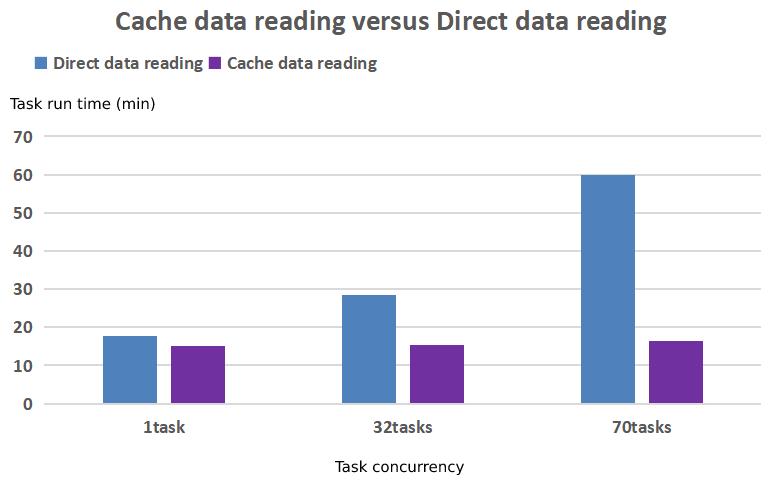
Die Strategien der „Null-Kopie“-Übertragung, des Multi-Thread-Abrufs, der inkrementellen Datenaktualisierung und der Affinitätsplanung für Trainingsdaten verkürzen den Daten-Cache-Zyklus erheblich und verbessern die Effizienz der Modellentwicklung und des Trainings.

Unterstützt die Erweiterung des verteilten Trainings durch MPI in TensorFlow, PyTorch und anderen Mainstream-Frameworks und bietet Standard-UI-Operationen, sodass Benutzer verteiltes Training durch einfache GPU-Ressourcen und Trainingsskriptkonfigurationen einreichen können.

Bietet Fehlertoleranz für Trainingsaufgaben und ermöglicht es der Plattform, ein kontinuierliches Training von Aufgaben zu gewährleisten und die Wiederherstellungszeit im Falle eines Serverabsturzes oder GPU-Ausfalls zu verkürzen.

Please enter the SN or MN code of your product to preview or download it.
Verification code:
By clicking Submit,you acknowledge that you agree to comply with all applicable laws and regulations.



KAYTUS verwendet Cookies, um die Nutzung der Website zu ermöglichen und zu optimieren, Inhalte zu personalisieren und die Nutzung der Website zu analysieren. Weitere Informationen finden Sie in unserer Datenschutzrichtlinie.
 Kontakt
Kontakt
