AIStation est une plateforme DevOps d'IA conçue par KAYTUS pour le développement et le déploiement de modèles d'IA. Elle aide les entreprises à créer des plateformes efficaces de développement de l'apprentissage profond, à gérer et à planifier les ressources informatiques d'IA de manière unifiée, et à améliorer efficacement l'utilisation des ressources informatiques. AIStation fournit aux développeurs d'IA une pile complète de logiciels de développement d'IA et un processus de développement, ce qui améliore considérablement l'efficacité de la recherche et du développement.

Une stratégie d'ordonnancement partagé du processeur graphique permet de partager les ressources du processeur graphique avec un seul appareil et de partager jusqu'à 64 tâches par processeur graphique. L'allocation et l'isolation à n'importe quelle granularité sont prises en charge. Les utilisateurs peuvent demander des ressources GPU de manière dynamique en fonction de la mémoire GPU.

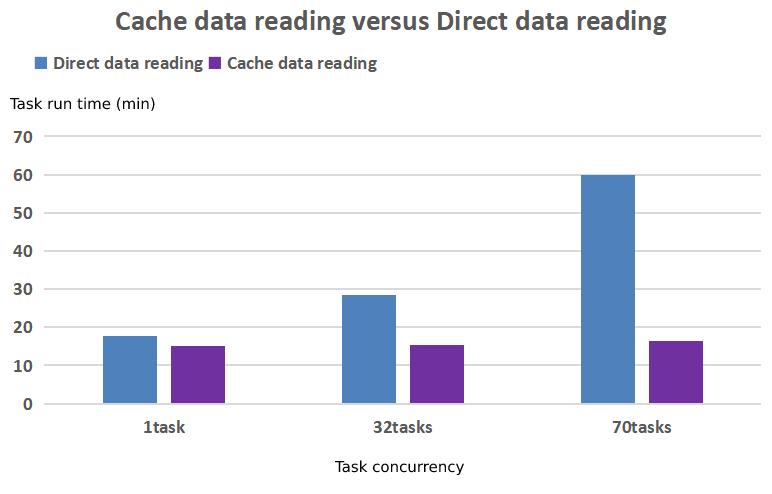
Les stratégies de transmission « zéro copie », de récupération à plusieurs fils, de mise à jour progressive des données et de planification des affinités pour les données d'entraînement raccourcissent considérablement le cycle de cache des données et améliorent l'efficacité du développement et de l'entraînement des modèles.

Prend en charge l'extension de la formation distribuée via MPI dans TensorFlow, PyTorch et d'autres cadres courants et fournit des opérations d'interface utilisateur standard, de sorte que les utilisateurs peuvent soumettre une formation distribuée par le biais de simples ressources GPU et de configurations de scripts de formation.

Fournit une tolérance aux pannes pour les tâches de formation, qui permettent à la plateforme d'assurer efficacement la formation continue des tâches et de réduire le temps de récupération en cas de panne du serveur ou de défaillance du GPU.

Please enter the SN or MN code of your product to preview or download it.
Verification code:
By clicking Submit,you acknowledge that you agree to comply with all applicable laws and regulations.



KAYTUS utilise des cookies pour permettre et optimiser l'utilisation du site web, personnaliser le contenu et analyser l'utilisation du site web. Veuillez consulter notre politique de confidentialité pour plus d'informations.
 Nous contacter
Nous contacter
