Full Stack AI
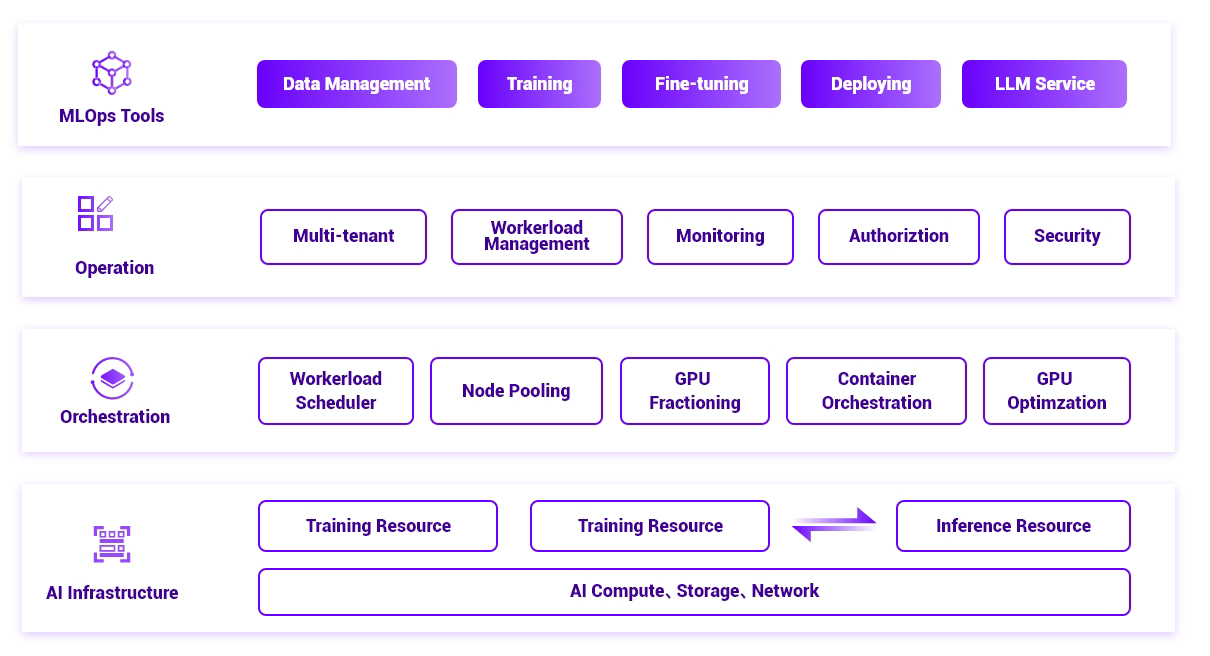
KAYTUS provides an industry-leading full-stack AI solution encompassing the AI infrastructure, resource platform and LLM tools. Through its full-stack AI capacity, KAYTUS provides strong AI compute power for various fields such as autonomous driving, meta-universe and drug development, and helps customers achieve orders of magnitude application performance improvement in voice, semantic, image, video, search, and network.
ToolChain: Focus on LLM scenarios, Data Processing(Filter, Generation, etc), Fine-tuning, RAG
· Resource Management & Scheduling
· Monitoring & Advanced Visualization
· Machine Learning Ops
· Batch cluster environment installation
· Cluster performance tuning
 AI computing cluster
AI computing cluster Parallel storage file system
Parallel storage file system RDMA Interconnect
RDMA Interconnect
Open up the whole process of large model training and reasoning, and lower the threshold of research and development

Performance tuning source, ChatGLM2, LLaMA2, Stable Diffusion, etc
Provide image generation and dialogue application solutions to help customers develop applications quickly

One-stop cluster delivery with automatic hardware-aware distributed training for optimal efficiency and scalability