MotusAI is an AI DevOps platform developed by KAYTUS for AI model development and deployment. It is dedicated to helping enterprises build efficient deep learning development platforms, manage and schedule AI computing resources in a unified manner, and effectively improve the utilization of computing resources. MotusAI provides AI development engineers with a complete AI development software stack and development process, greatly improving the R&D efficiency.

Provides fault tolerance for training tasks, enabling the platform to effectively ensure continuous training of tasks and reduce the recovery time in the event of a server crash or GPU failure.

Supports the extension of distributed training through MPI in TensorFlow, PyTorch and other mainstream frameworks and provides standard UI operations, so that users can submit distributed training through simple GPU resources and training script configurations.

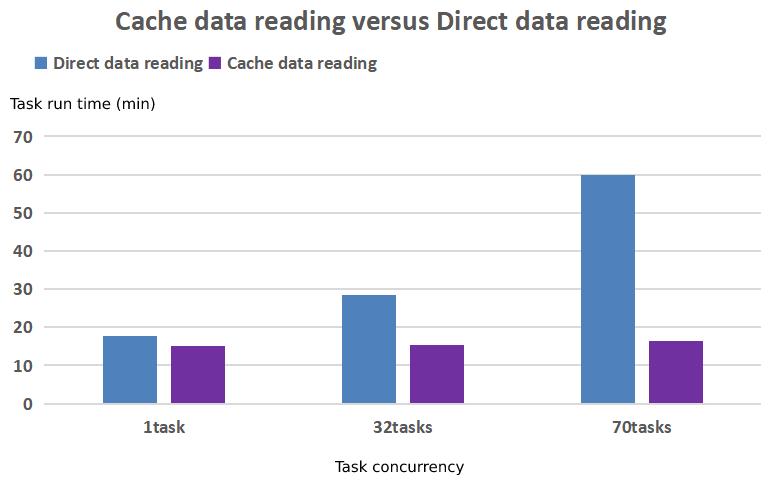
The strategies of "zero-copy" transmission, multi-thread fetch, incremental data update and affinity scheduling for training data greatly shorten the data cache cycle and improve efficiency of model development and training.

A GPU shared scheduling strategy provides single-device sharing of GPU resources and supports the sharing of up to 64 tasks per GPU. Allocation and isolation at any granularity are supported. Users can dynamically request GPU resources based on the GPU memory.

Please enter the SN or MN code of your product to preview or download it.
Verification code:
By clicking Submit,you acknowledge that you agree to comply with all applicable laws and regulations.


Contact Us

TOP
KAYTUS uses cookies to enable and optimize the use of the website, personalize content and analyze the website usage. Please see our privacy policy for more information.
 Contact Us
Contact Us
